Clean Code 1: Frustrations with School
Posted: 2023-03-24
At time of writing, I am currently grappling with some of the most frustrating assignments that I have ever worked on. SQL injections and recurrent neural networks sounded really cool to learn about. Turns out they're really difficult to make progress in. Such are most things that are interesting. But the amount I could complain about transformers right now...
That's not the main topic of this post though. Here are my thoughts after reading the couple chapters of Clean Code.
Chapter 1 - Clean Code
At the very start of the chapter, we've already hit some interesting philosophical discussion points. There is one big point that stands out to me: that there will always be code.
Recent revolutions in AI text generation have obviously made the news. I am not debating the fact that there will always be code; in fact, I quite like Martin's definition of code:
"[S]pecfiying requirements in such detail that a machine can execute them is programming. Such a specification is code."
What I wonder though, is how much longer will humans be writing the specification in a coding language instead of English? The various prompts to generate code for ChatGPT, for example, are already very close to pure English with little technical language involved. So even though code is being generated, the programmer is being taken out of the equation, slowly but steadily. I can see a future where software developers are geared towards writing prompts in English and simply evaluating the resulting code, rather than writing any code themselves. Any changes to the code would be made by going back to the AI and specifying further, in English.
While specifications will always need to exist, I'm not sure it will be helpful to label such a specification as code when it's written in plain English and then being translated to real code. At that point, Martin's definition becomes a bit superfluous.
Of course, reflecting back on this 15 years after it was written, much has changed. Few would have thought that such advanced text generation would be possible so soon. I don't fault Martin for saying code will never be generated by machines, just as I hope I won't be judged for some assumptions that I will inevitably make during this analysis of the book. Making predictions about the future with any sort of detail is hard.
But for now, code is still being written by humans using coding languages, so we'll continue spending time on learning how to write it better. On with the book.
Bad Code
There isn't much to say about the actual text of the book here, other than it's super accurate. The feeling of wading through bad code and trying to make sense of it is certainly something I'm familiar with, due to courses and past internships.
I feel like this really strikes a chord with me right now because of the assignments I'm working on. One of the assignments is based off of example code that was obviously not designed to be modified or extended. The problem is the assignment consists entirely of extending the functionality of the codebase.
The intent to redesign the old codebase definitely crossed my mind, but yet again, the book describes the situation very accurately. The redesign would have had to do everything the old codebase did, plus the new extensions required by the assignment. I wanted to make the code more modular and more readable, but in the end I had to stop and actually work on the goals of the assignment, simply because the rework took too long.
Given that the assignment's topic is already difficult, this has been quite a weight on my shoulders for the last few days. I really resonate with being slowed down by someone else's messy code right now, so I think this was a good time to start reading this book.
Definitions of Clean Code
Wow. Many quotes from many storied developers, all with their own definition of what makes good code. It's quite interesting to see what each person mentions.
The biggest takeaway here is that there are many definitions of what clean code looks like, none of which are necessarily wrong. I like this a lot. Everyone is going to have their own philosophy.
Martin goes on to say:
"[M]any of the recommendations in this book are controversial. You will probably not agree with all of them... That's fine. We can't claim final authority... So whether you agree or disagree, it would be a shame if you did not see, and respect, our point of view."
I always try to go in with an open mind when it comes to any sort of opinion, and it's nice to see this explicitly pointed out here. I'm definitely not going to agree with everything written in this book (I've already pointed out a disagreement above), but as mentioned, that's fine.
So far, so good.
Chapter 2 - Meaningful Names
Ah, naming. Naming is hard. A common joke that goes around indie dev circles is how devs will agonize over choosing a name for their game or company, all before writing a single line of code.
Most of the advice is good. Making names obvious and representative of what they are for is definitely important. Names should reveal the purpose of a variable, function, or class, without needing to read the rest of the code.
Making names distinct from each other, pronounceable, and searchable is huge for speeding up work in general. Being consistent throughout your code is also important; sticking with a consistent get for getters looks nicer and gives information much faster than using multiple synonyms at the same time.
Getting down to class and interface names, I still agree but slightly less. I think indicating that something is an interface is useful for getting information at a glance, although I agree that the preceding I can be missed too easily. Something like starting with Interface would be nice. I won't contest adding something to the implementation instead though.
Classes and objects should have nouns as a name in general. However, Martin gives Manager and Processor as examples of what to avoid in naming a class, despite the fact that these are nouns. I don't agree - sometimes that's what a class does, such as a DataManager class. In this example, I would argue that having all the code to actively manage data in one place would be cleaner than having it scattered throughout multiple classes, and it would definitely be nicer than obfuscating the name to avoid the banned nouns, such as DataStorerLoaderSenderAndReceiver. Not to mention the very next page continues to use Manager in class names.
But I digress. This is pretty nitpicky.
The last couple things are fine. Method names should have verb or verb phrase names - this makes sense, since they should be doing something. Don't use the same word for multiple meanings, since ambiguity is bad.
Code Samples
Now we get to the first code samples of the book at the end of this chapter. There are two samples, one with supposedly unclear variable context, and an improved version with context for the variables.
I'm going to go in depth with my thoughts about these samples. I won't write as much as this for later samples that I want to talk about, but since this is the first one, I feel like I should lay out my entire thought process.
The first sample is as such:
private void printGuessStatistics(char candidate, int count) {
String number;
String verb;
String pluralModifier;
if (count == 0) {
number = "no";
verb = "are";
pluralModifier = "s";
} else if (count == 1) {
number = "1";
verb = "is";
pluralModifier = "";
} else {
number = Integer.toString(count);
verb = "are";
pluralModifier = "s";
}
String guessMessage = String.format(
"There %s %s %s%s", verb, number, candidate, pluralModifier
);
print(guessMessage);
}
My first thoughts were, "OK. This isn't the greatest function or variable naming, since it's not clear what their purposes are until you look through the code. I could definitely see how this could be improved." So as an exercise, I reworked the function a little. I wanted to compare my work to Martin's example of good code to see how I could improve. I'll compare my changes/suggestions to Martin's code as we analyze it below.
This is Martin's improved code, where variables now have a context:
public class GuessStatisticsMessage {
private String number;
private String verb;
private String pluralModifier;
public String make(char candidate, int count) {
createPluralDependentMessageParts(count);
return String.format(
"There %s %s %s%s",
verb, number, candidate, pluralModifier );
}
private void createPluralDependentMessageParts(int count) {
if (count == 0) {
thereAreNoLetters();
} else if (count == 1) {
thereIsOneLetter();
} else {
thereAreManyLetters(count);
}
}
private void thereAreManyLetters(int count) {
number = Integer.toString(count);
verb = "are";
pluralModifier = "s";
}
private void thereIsOneLetter() {
number = "1";
verb = "is";
pluralModifier = "";
}
private void thereAreNoLetters() {
number = "no";
verb = "are";
pluralModifier = "s";
}
}
Hm.
Creating a class makes sense, since there are lots of related methods and variables, so we should group those all together. To be fair to Martin, the variables have a clear context now. The interface is also obvious - there's one function that users can call, which is make.
But what isn't obvious?
This chapter was about naming, right? We had a lot of rules, most of which I agreed with, about how names should be obvious in their meaning and distinct from each other, just at a quick glance.
First off, Martin didn't even change the variable names, which was something that jumped out at me as being unclear in their meaning. pluralModifier is fine, but what do number and verb represent? It's obvious if you read the code, but wasn't that something we were supposed to avoid? I would have changed number to numberOfLetters and verb to verbConjugation. Could be a little wordy, but at least now it's obvious.
make is rather short, but I'll excuse it since calling GuessStatisticsMessage.make() is obvious enough. That's the least problematic of the method names.
createPluralDependentMessageParts - what? I had to read this a few times before I even understood what the method name was saying. Part of this is thanks to the English language, as I read it as "Plural" "Dependent Message Parts" rather than "Plural-Dependent" "Message Parts". But surely we could rename this to remove that ambiguity? I think createPluralPartsOfMessage or even createMessagePartsThatDependOnPlurals would work better.
Then we have the three later methods. thereAreManyLetters, thereIsOneLetter, and thereAreNoLetters. These are pretty similar, but let's ignore that rule (which we've already broken) about meaningful distinctions between names.
These methods all change member variables of the class, but that isn't indicated anywhere in the names of the methods. Hello, unforeseen side effects.
There's more - all the method names are just statements. Didn't Martin have some rules about method naming earlier?
"Methods should have verb or verb phrase names."
Then what happened here? Why are we breaking rules that we just stated and restated at length? They're good rules!
Why didn't he just continue the pattern he already started, like he mentioned you should? We already had "create...." as a template for naming our methods. So why not createNoLetterMessageParts or something similar?
Not to mention, where did the letter part of the method name come from? If we're counting letters (which we may very well be, but the only indication is from make accepting a char as the candidate parameter), then why did we name the class GuessStatisticsMessage instead of CreateMessageForNumberOfLetters? We're already renaming everything, no need to keep the spirit of the original function name.
I've also just realized GuessStatisticsMessage is a verb phrase, not a noun. There goes another rule.
From earlier in the chapter:
"We want our code to be a quick skim, not an intense study."
Great words to live by, but this "good" code sample completely trashes this advice.
Overall Reflections
We had good rules. A couple of disagreements, but good rules. The code examples though... Oh boy. I really hope the rest of the book is better than this.
After the first couple of chapters, I assume this book is targeted at beginners. It's possible there are some more experienced devs that haven't heard these rules before, but really it's going to be juniors that don't know these rules and will be learning them for the first time.
What's concerning then, is that juniors are going to be reading this chapter and find that it's logical and enlightening. Then they'll come to the code sample and either find it super confusing, or they'll take it at face value and assume that's good code. Either case is not good for people just getting started in professional development. We'll see if this pattern of good rules and bad examples continues, because at least then there's a simple guideline to follow when reading Clean Code. Only time will tell.
As mentioned earlier, it's okay to disagree with the recommendations in this book. My issue wasn't with the recommendations (i.e. the listed rules); it was with the examples that blatantly disregarded the recommendations.
Phew. That was a lot of analysis on not a very long excerpt. Back to the terrible, unextensible assignment codebase. It's a good reminder that it could always be worse.
Click me for some extras!
I touched on AI text generation earlier, so that made me curious. I passed in the original code sample to ChatGPT and asked it to clean it up.
This is what it gave me:
/**
* Prints a message stating how many characters that match the given candidate character exist.
* @param candidate the character to search for
* @param count the number of characters that match the candidate
*/
private void printGuessStatistics(char candidate, int count) {
// Set the appropriate number, verb, and plural modifier based on the count
String number;
String verb;
String pluralModifier;
if (count == 0) {
number = "no";
verb = "are";
pluralModifier = "s";
}
else if (count == 1) {
number = "1";
verb = "is";
pluralModifier = "";
}
else {
number = Integer.toString(count);
verb = "are";
pluralModifier = "s";
}
// Construct and print the message
String message = String.format("There %s %s %s%s", verb, number, candidate, pluralModifier);
print(message);
}
Yeah, this looks almost identical to the original code sample, now with comments. I tried a few times to get it to do some renaming and refactoring, but it repeatedly came out with basically the same result.
Something that was interesting was that it kept claiming that it made certain changes, such as renaming the variables and adding comments, when it really didn't. It was only after some prodding that it did so. And the last attempt actually undid a lot of its work, so I've actually pasted in the second last attempt here.
In case you're curious, here's the full conversation I had.
This doesn't destroy my prediction about the future - AI text generation has come a LONG way in the last few years - but I'm fairly comfortable in saying that AI isn't going to replace regular humans writing code using a coding language in the near future.
Anyway, back to my recurrent neural networks assignment.
...which brings up one last aside. The assignment has a question where we're training a model to translate between different languages. After training, one of the test sentences was to translate "tu es incroyable" to English.
The actual translation is "you're amazing". The RNN? "You're weird". And then "il est innocent" got turned into "he's drunk".
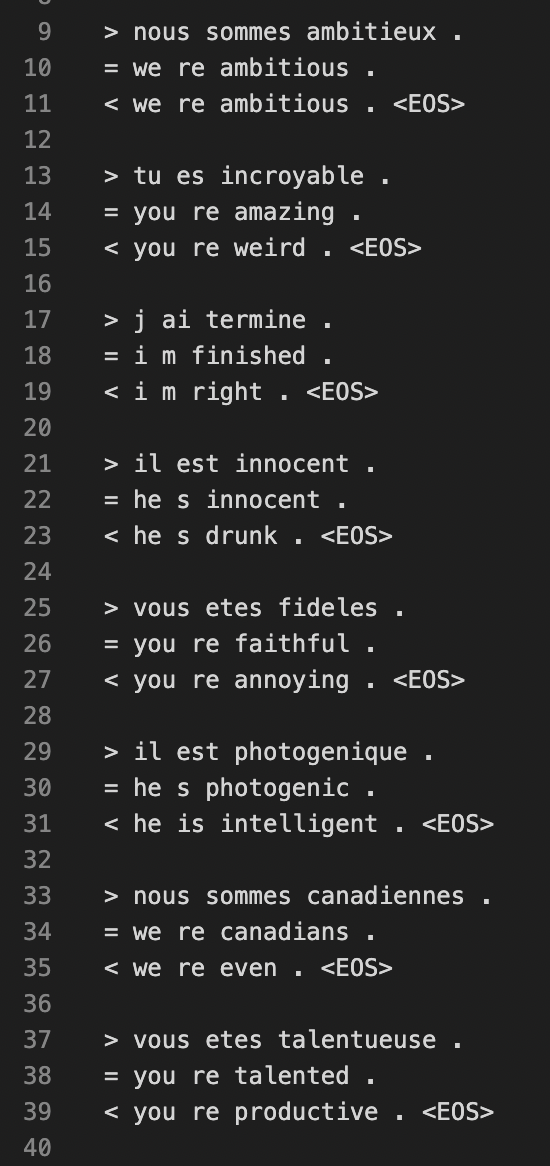
Yeah. Still a ways to go.